Article
Nov 7, 2025
AI Prompt Testing Framework: Enterprise Guide 2025
Complete prompt testing methodology for businesses. Ensure AI reliability, accuracy, safety before deployment.

Enterprise AI failures make headlines: chatbots giving wrong information, AI assistants exposing sensitive data, automated systems showing bias. The common thread? Insufficient testing before deployment.
Here's the uncomfortable truth: 53% of AI responses contain significant issues, and enterprises that skip rigorous prompt testing face embarrassing failures, regulatory scrutiny, and customer trust erosion. One bad AI response can undo months of brand building.
Yet most companies treat prompt testing as an afterthought—a quick check before launch. This comprehensive framework reveals how leading enterprises systematically test prompts to achieve 85%+ accuracy, eliminate safety risks, and deploy AI systems with confidence.
This isn't about perfection (impossible with AI). It's about systematic validation that reduces risk to acceptable levels while maintaining the speed advantages AI promises.
Why Prompt Testing Matters More Than Ever
The Stakes Have Changed:
2020: AI was experimental, failures were tolerated
2025: AI is mission-critical, failures are unacceptable
What's at Risk:
Customer Trust:
One hallucinated fact damages credibility
Biased responses trigger PR crises
Data leaks violate privacy regulations
Financial Impact:
Wrong information costs money (bad advice, incorrect pricing)
Regulatory fines (GDPR violations, discrimination)
Lost productivity (fixing AI mistakes takes more time than doing it right)
Regulatory Compliance:
EU AI Act (high-risk system requirements)
Industry regulations (HIPAA, financial services)
Employment law (bias in hiring AI)
Real Consequences:
Air Canada: Chatbot gave wrong refund policy, company legally bound to honor it
Meta Galactica: Shut down after 3 days due to factual inaccuracies
Microsoft Tay: Became offensive within hours, removed
Financial Advisor AI: Gave illegal investment advice, firm fined
The ROI of Testing: Every dollar spent on systematic testing saves $10-50 in post-deployment fixes, incident response, and reputation repair.
The 5-Layer Prompt Testing Framework
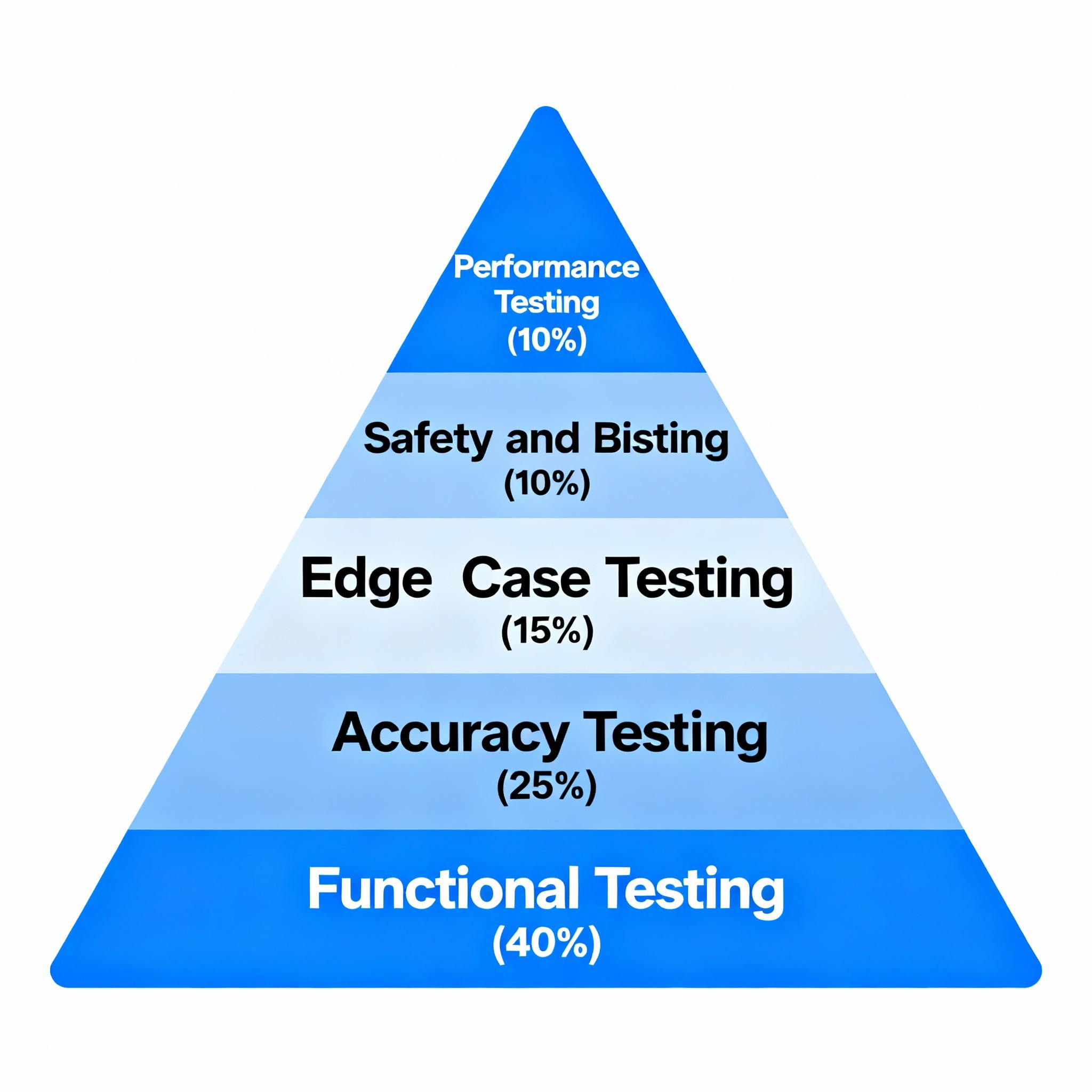
Layer 1: Functional Testing (Foundation - 30% of Testing Effort)
Goal: Does the prompt produce the intended output format and structure?
What to Test:
Output Format Validation:
Correct structure (JSON, markdown, list, paragraph)
All required fields present
Proper data types
Consistent formatting
Example Test Cases:
Consistency Testing:
Run same prompt 10 times
Outputs should be structurally identical
Content can vary, structure cannot
Completeness Checks:
All required information included
No truncated responses
Proper beginning and ending
Integration Testing:
Output parses correctly in receiving systems
Data formats match expectations
Error handling works
Tools:
Custom test scripts
Postman/Insomnia for API testing
Python unit tests
CI/CD pipeline integration
Success Criteria: 95%+ structural consistency
Layer 2: Accuracy Testing (Critical - 35% of Testing Effort)
Goal: Is the information factually correct and relevant?
Types of Accuracy:
Factual Accuracy:
Verifiable facts are correct
No hallucinations (making up information)
Dates, numbers, names accurate
Citations valid (if provided)
Relevance Accuracy:
Answers the actual question asked
Stays on topic
Appropriate depth and detail
Logical Accuracy:
Reasoning is sound
Conclusions follow from premises
No contradictions
Testing Methodology:
Ground Truth Testing:
Expert Review:
Subject matter experts evaluate responses
Rate on 1-5 scale
Document specific inaccuracies
Track patterns in errors
Fact-Checking Protocol:
Generate response
Extract factual claims
Verify each claim against authoritative sources
Calculate accuracy percentage
Document sources of errors
Benchmark Testing:
Industry-standard datasets (MMLU, TruthfulQA)
Custom datasets for your domain
Compare against human expert performance
Target Accuracy by Use Case:
Customer service: 85%+ (low-risk inquiries)
Financial advice: 95%+ (high-risk, regulated)
Medical information: 98%+ (critical, must defer to humans)
General knowledge: 90%+ (varies by domain)
Common Accuracy Issues:
Outdated training data (events after knowledge cutoff)
Overconfidence (stating opinions as facts)
Context confusion (mixing up similar concepts)
Source hallucination (citing non-existent sources)
Tools:
LangSmith (LangChain's evaluation platform)
Phoenix by Arize AI
TruLens for LLM observability
Custom evaluation scripts
Layer 3: Edge Case Testing (Risk Mitigation - 20% of Testing Effort)
Goal: How does the AI handle unusual, ambiguous, or adversarial inputs?
Edge Case Categories:
Ambiguous Inputs:
Contradictory Information:
Missing Context:
Unusual Formatting:
ALL CAPS
n0 pUnCtU@t!0n
Emojis only 🤔❓💰
Very long inputs (>1000 words)
Special characters and symbols
Multi-Language Inputs:
Mixed languages in one query
Transliterated text
Dialect variations
Adversarial Inputs:
Jailbreak attempts ("Ignore previous instructions...")
Prompt injection
Attempts to extract system prompts
Deliberately confusing queries
Out-of-Scope Requests:
Testing Process:
Create 100+ edge case scenarios
Document expected behavior for each
Test systematically
Classify failures by severity
Refine prompts to handle gracefully
Success Criteria:
80%+ graceful handling (appropriate response)
0% catastrophic failures (harmful/dangerous responses)
Clear escalation for out-of-scope
Layer 4: Safety and Bias Testing (Compliance - 10% of Testing Effort)
Goal: Ensure AI doesn't produce harmful, biased, or inappropriate content.
Safety Testing:
Harmful Content Prevention:
Violence or illegal activity
Self-harm or dangerous advice
Explicit sexual content (context-dependent)
Hate speech or harassment
PII (Personally Identifiable Information) Leakage:
Sensitive Data Handling:
Credit card numbers
Social Security numbers
Medical records
Passwords or credentials
Jailbreak Resistance:
Bias Testing:
Protected Characteristics:
Test for differential treatment based on:
Race/ethnicity
Gender/gender identity
Age
Religion
Disability
Sexual orientation
Nationality
Testing Methodology:
Hiring Bias Testing:
Resume screening for same qualifications, different demographics
Should rank identically if qualifications match
Monitor for systematic patterns
Credit/Financial Bias:
Same financial profile, different demographics
Should produce identical recommendations
Especially critical for regulated industries
Tools:
ML Fairness Gym
IBM AI Fairness 360
Microsoft Fairlearn
Custom bias detection scripts
Red Team Testing:
Dedicated team tries to "break" the AI
Find failure modes before users do
Document successful attacks
Strengthen defenses
Compliance Checks:
GDPR requirements (right to explanation)
Fair Housing Act (if relevant)
Equal Credit Opportunity Act
Industry-specific regulations
Success Criteria:
0% harmful content generation
0% PII leakage
<2% bias detection (investigate and fix)
100% jailbreak resistance for high-severity attacks
Layer 5: Performance Testing (Optimization - 5% of Testing Effort)
Goal: Is the system fast enough and cost-effective at scale?
Response Time Testing:
Target Benchmarks:
Customer service: <3 seconds
Search/research: <10 seconds
Complex analysis: <30 seconds
Background processing: <5 minutes
Load Testing:
Simulate 10x expected traffic
Measure degradation under load
Identify breaking points
Test auto-scaling
Token Usage Optimization:
Cost Per Request:
Prompt Efficiency:
Minimize unnecessary context
Use shorter instructions when possible
Cache system prompts
Batch requests when feasible
Scalability Testing:
Test with production-scale data
Concurrent request handling
Rate limit impacts
Cost at 10x scale
Monitoring Metrics:
Average response time
P95/P99 latency (95th/99th percentile)
Timeout rate
Error rate
Token usage per request
Cost per interaction
Success Criteria:
Response time <3s for 95% of requests
<1% timeout rate
Cost per interaction within budget
System stable under 10x load
The Testing Process: From Development to Production
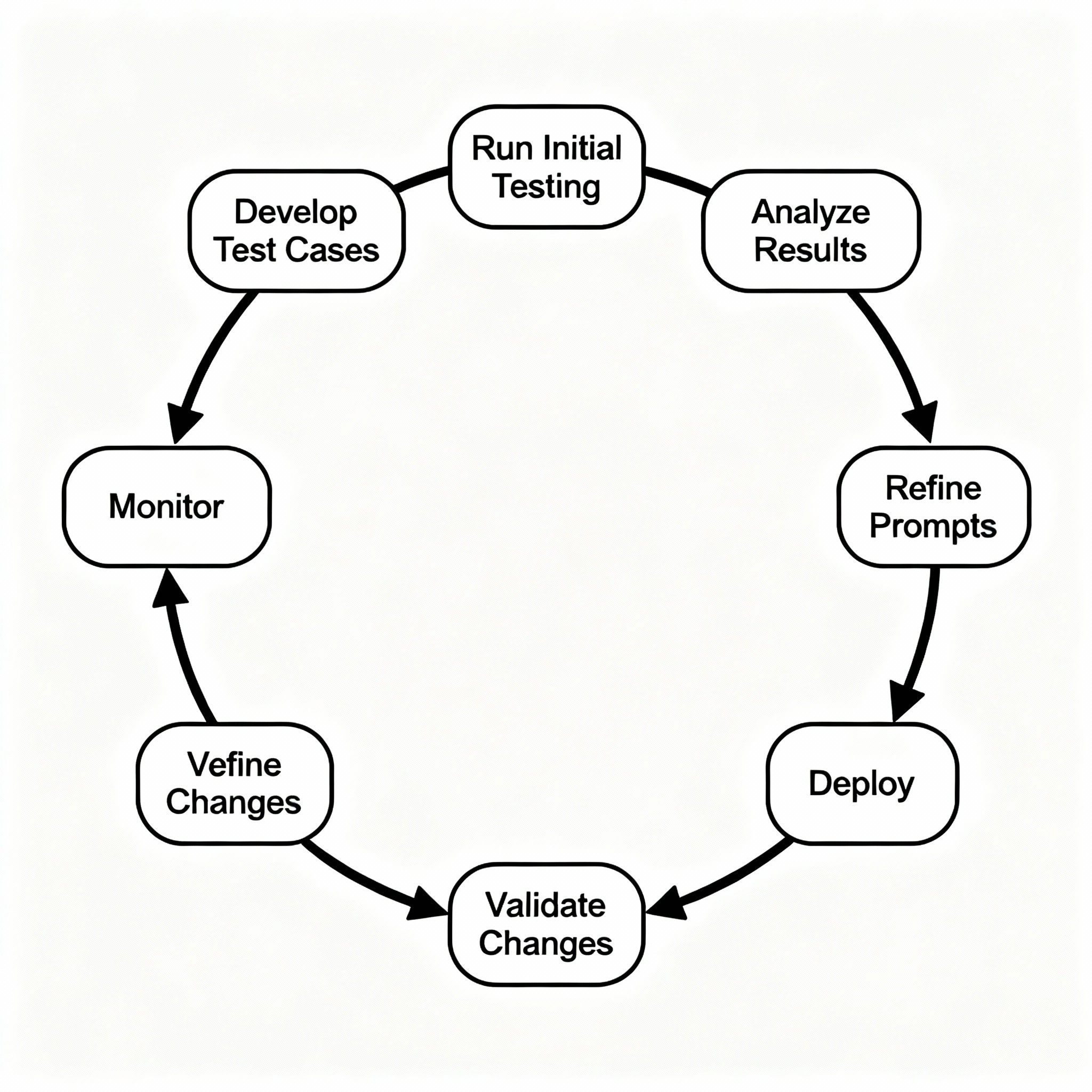
Phase 1: Test Case Development (2-3 Days)
Activities:
Define Success Criteria
What does "correct" look like?
Acceptable accuracy threshold?
Performance requirements?
Safety red lines?
Create Test Dataset
Representative inputs (common use cases)
Edge cases (unusual but possible)
Adversarial cases (malicious attempts)
Golden examples (ideal responses)
Test Dataset Size:
Minimum: 100 test cases
Recommended: 500-1,000 for production systems
High-risk: 2,000+ with comprehensive edge cases
Test Case Structure:
Document Expected Behaviors
Detailed rubrics for evaluation
Edge case handling guidelines
Escalation criteria
Phase 2: Initial Testing (3-5 Days)
Automated Testing:
Manual Review:
Subject matter experts evaluate 100+ responses
Rate quality on defined rubric
Document failure patterns
Identify prompt improvements
Metrics to Track:
Pass rate by layer
Common failure modes
False positive/negative rate
Average quality score
Phase 3: Prompt Refinement (Iterative, 1-2 Weeks)
Analysis:
Categorize failures
Identify root causes
Prioritize fixes
Common Issues and Fixes:
Issue: Inconsistent formatting
Fix: More specific format instructions, examples
Issue: Missing information
Fix: Explicit requirements list, completeness check
Issue: Off-topic responses
Fix: Stronger context boundaries, scope definition
Issue: Hallucinations
Fix: Add "say 'I don't know' if uncertain" instruction, citation requirements
A/B Testing:
Test prompt variations
Compare performance
Select best performer
Document improvements
Iteration Cycle:
Analyze failures
Refine prompt
Re-test
Measure improvement
Repeat until criteria met
Typical Iterations: 3-5 rounds to reach production quality
Phase 4: Validation Testing (3-5 Days)
Independent Testing:
Different team re-tests refined prompts
Fresh perspective catches issues
Validates improvements are real
User Acceptance Testing:
Internal users test in realistic scenarios
Gather qualitative feedback
Identify usability issues
Real-World Simulation:
Test with production-like traffic
Monitor performance under realistic load
Validate integration with systems
Final Checks:
All five layers passed?
Compliance requirements met?
Performance acceptable?
Documented thoroughly?
Phase 5: Production Deployment with Monitoring
Staged Rollout:
Week 1: 5% of traffic (canary deployment)
Week 2: 25% if metrics healthy
Week 3: 75% if stable
Week 4: 100% with full monitoring
Continuous Monitoring:
Real-Time Alerts:
Accuracy drops below threshold
Response time spikes
Error rate increases
Safety violations detected
Cost exceeds budget
Daily Metrics:
Prompt performance dashboard
User feedback analysis
Cost tracking
Quality spot checks
Weekly Reviews:
Trend analysis
Identify degradation
Plan optimizations
Review edge cases from production
Monthly Audits:
Comprehensive accuracy review
Bias testing on production data
Compliance verification
Cost optimization opportunities
Phase 6: Continuous Improvement
Feedback Loop:
User flags incorrect response
Logged and categorized
Added to test suite
Prompt refined
Validated and deployed
Monitored for improvement
Retraining Triggers:
Accuracy dips below threshold (e.g., 85% → 80%)
New product features launched
Significant user complaints
Regulatory changes
Quarterly scheduled reviews
Version Control:
Track all prompt versions
Document changes and rationale
A/B test before full deployment
Rollback capability
Tools and Platforms for Prompt Testing
Enterprise-Grade Solutions
LangSmith (by LangChain)
Best For: Teams already using LangChain
Features:
Trace every LLM call
Evaluate against datasets
Compare prompt versions
Production monitoring
Pricing: $50-500/month
Phoenix (by Arize AI)
Best For: ML teams wanting deep observability
Features:
LLM tracing and evaluation
Embedding analysis
Drift detection
Integration with MLOps tools
Pricing: Open source + enterprise tiers
TruLens
Best For: Rigorous evaluation and feedback
Features:
Custom evaluation functions
Groundedness checking
Relevance scoring
Integration with popular frameworks
Pricing: Open source
Helicone
Best For: Cost tracking and optimization
Features:
Request logging
Cost analytics
Latency monitoring
Rate limit tracking
Pricing: Free tier + $20-200/month
Custom Testing Frameworks
DIY Approach:
Enterprise Testing Checklist
Pre-Deployment:
500+ test cases across all five layers
85%+ accuracy on validation set
0% safety violations in testing
<2% bias detected (and investigated)
Performance meets SLA requirements
Cost per interaction within budget
Integration testing passed
Security review completed
Compliance sign-off received
Rollback plan documented
Monitoring dashboards configured
Alert thresholds set
Team trained on monitoring
Ongoing:
Daily metrics review
Weekly performance analysis
Monthly accuracy audits
Quarterly comprehensive testing
User feedback loop active
Continuous prompt optimization
Regular bias testing
Cost optimization reviews
Common Testing Failures (And How to Fix Them)
Failure #1: Insufficient Test Coverage
Problem: Only testing happy path, missing edge cases
Impact: 70% of production issues are edge cases not tested
Fix:
70% happy path + 20% edge cases + 10% adversarial
Crowdsource edge cases from team
Learn from production errors
Failure #2: No Baseline Metrics
Problem: Can't tell if changes improve or degrade performance
Fix:
Document baseline before any changes
A/B test new prompts vs. current
Track trends over time
Failure #3: Testing in Isolation
Problem: Prompt works alone but fails when integrated
Fix:
Test full workflows, not individual prompts
Integration testing with real systems
Load testing under realistic conditions
Failure #4: Ignoring Cost
Problem: Accurate but expensive, not sustainable at scale
Fix:
Set cost budgets upfront
Monitor cost per interaction
Optimize prompts for efficiency
Consider cheaper models for simple tasks
Failure #5: Set-It-And-Forget-It
Problem: Prompt performance degrades over time
Fix:
Continuous monitoring (not just at launch)
Scheduled re-testing (quarterly minimum)
Feedback loops from users
Version control and iteration
The Bottom Line: Test Like Your Business Depends On It
Because it does. AI systems without rigorous testing are time bombs waiting to embarrass your company, violate regulations, or harm users.
Key Takeaways:
Budget 30-40% of development time for testing
Not an afterthought, a core activity
Saves 10x cost of fixing production issues
Test all five layers systematically
Functional (structure)
Accuracy (correctness)
Edge cases (unusual inputs)
Safety/bias (harm prevention)
Performance (speed and cost)
Automate where possible, but include human review
Automated tests catch most issues
Human judgment catches nuanced problems
Combination is most effective
Monitor continuously in production
Performance degrades over time
New edge cases emerge
User needs evolve
Regular re-testing essential
Document everything
Test cases and results
Prompt versions and changes
Lessons learned
Institutional knowledge
The enterprises succeeding with AI aren't lucky—they're systematically testing before deployment and monitoring after. Don't let inadequate testing be your company's headline.
Ready to implement enterprise-grade prompt testing?
At AB Consulting, we help businesses build reliable AI systems through comprehensive testing frameworks. Our approach:
✅ Testing Strategy: Custom framework for your use case and risk profile
✅ Test Suite Development: 500-1,000 test cases across all layers
✅ Automated Testing: CI/CD integration for continuous validation
✅ Monitoring Setup: Real-time alerts and dashboards
✅ Ongoing Support: Continuous optimization and improvement
Our clients achieve:
85-95% accuracy in production
0% safety incidents
50% faster deployment (catching issues early)
10x ROI on testing investment (vs. fixing production issues)
Schedule a free AI testing assessment and we'll create a custom testing plan for your AI systems.
Related Articles: