Article
Nov 7, 2025
Mastering AI Prompts: The Complete Guide to Prompt Engineering in 2025
Master prompt engineering with proven frameworks, techniques, and strategies. Learn to craft effective AI prompts for ChatGPT, Claude, and other LLMs to achieve professional results.

Prompt engineering has evolved from a niche skill into a fundamental competency for anyone working with artificial intelligence. As AI models become more sophisticated and accessible, the ability to communicate effectively with them determines whether you extract transformative value or frustrating mediocrity. This comprehensive guide distills cutting-edge research, professional best practices, and real-world testing into actionable strategies for mastering prompt engineering in 2025.
Understanding Prompt Engineering Fundamentals
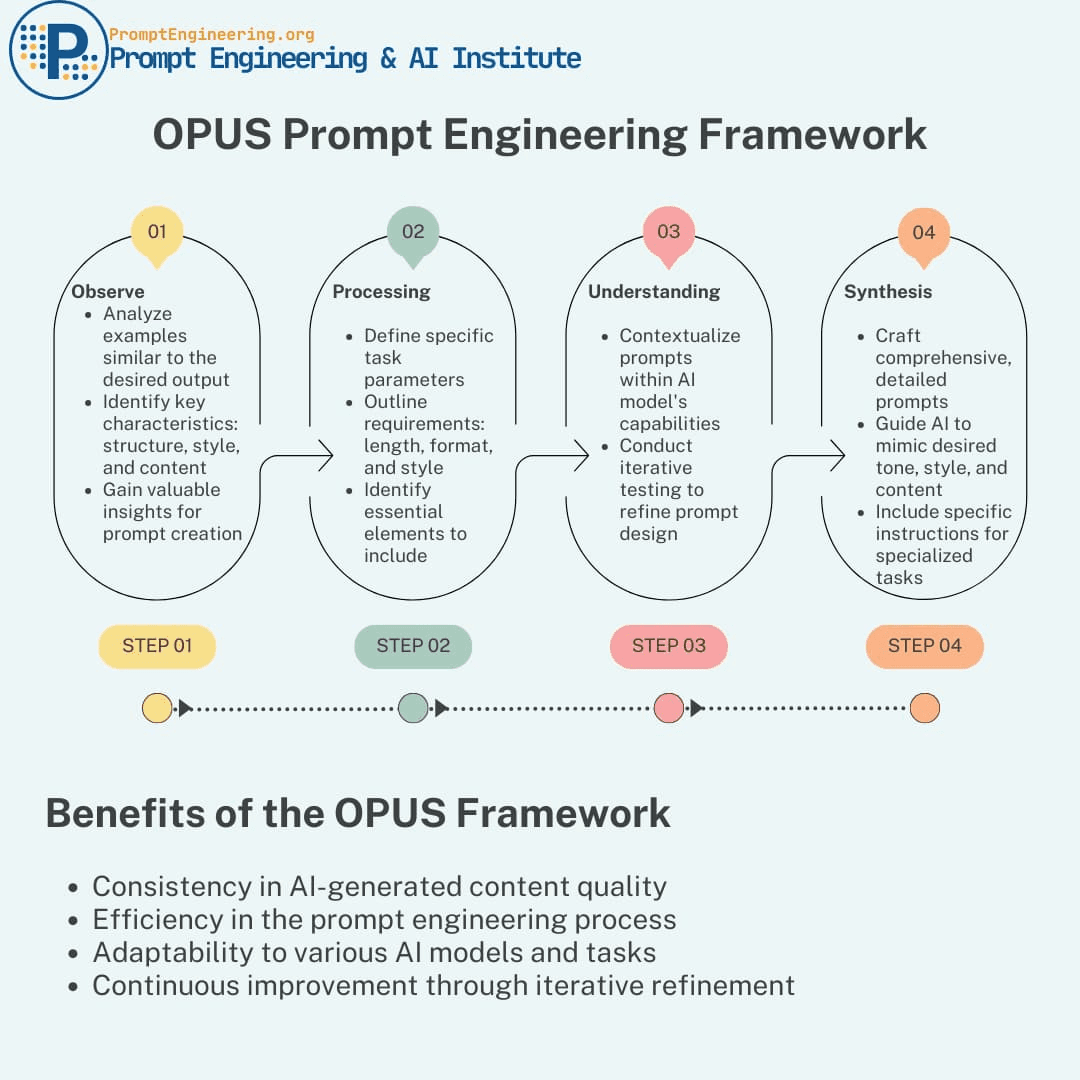
Prompt engineering is the art and science of designing inputs that guide AI models toward generating desired outputs. Unlike traditional programming where you specify exact logic, prompt engineering works through natural language instruction, context provision, and strategic framing.
The importance of mastering this skill cannot be overstated. Research demonstrates that well-engineered prompts can dramatically improve output quality without retraining models or adding more data. For businesses, effective prompting translates directly to ROI—companies report generating $3.70 for every $1 invested in AI when prompt engineering is done correctly.
Why Prompt Quality Matters
The quality of your prompt directly determines:
Output Accuracy: Specific, well-structured prompts yield precise responses aligned with your needs. Vague inputs generate generic, often unhelpful results.
Consistency: Standardized prompting approaches ensure reliable outputs across multiple interactions. Without structure, you get unpredictable variance that undermines trust.
Efficiency: Effective prompts minimize iteration cycles, reducing time spent refining unsatisfactory responses. Poor prompts waste computational resources and human effort.
Safety and Compliance: Properly engineered prompts incorporate guardrails that prevent harmful outputs, maintain appropriate tone, and respect ethical boundaries.
Core Prompt Engineering Techniques
Zero-Shot Prompting: Leveraging Base Knowledge
Zero-shot prompting instructs AI models to perform tasks without providing examples, relying entirely on the model's training data and understanding of natural language.
When to use: Simple, straightforward tasks where the model's base knowledge suffices. Information retrieval, basic summarization, and general knowledge queries work well zero-shot.
Example:
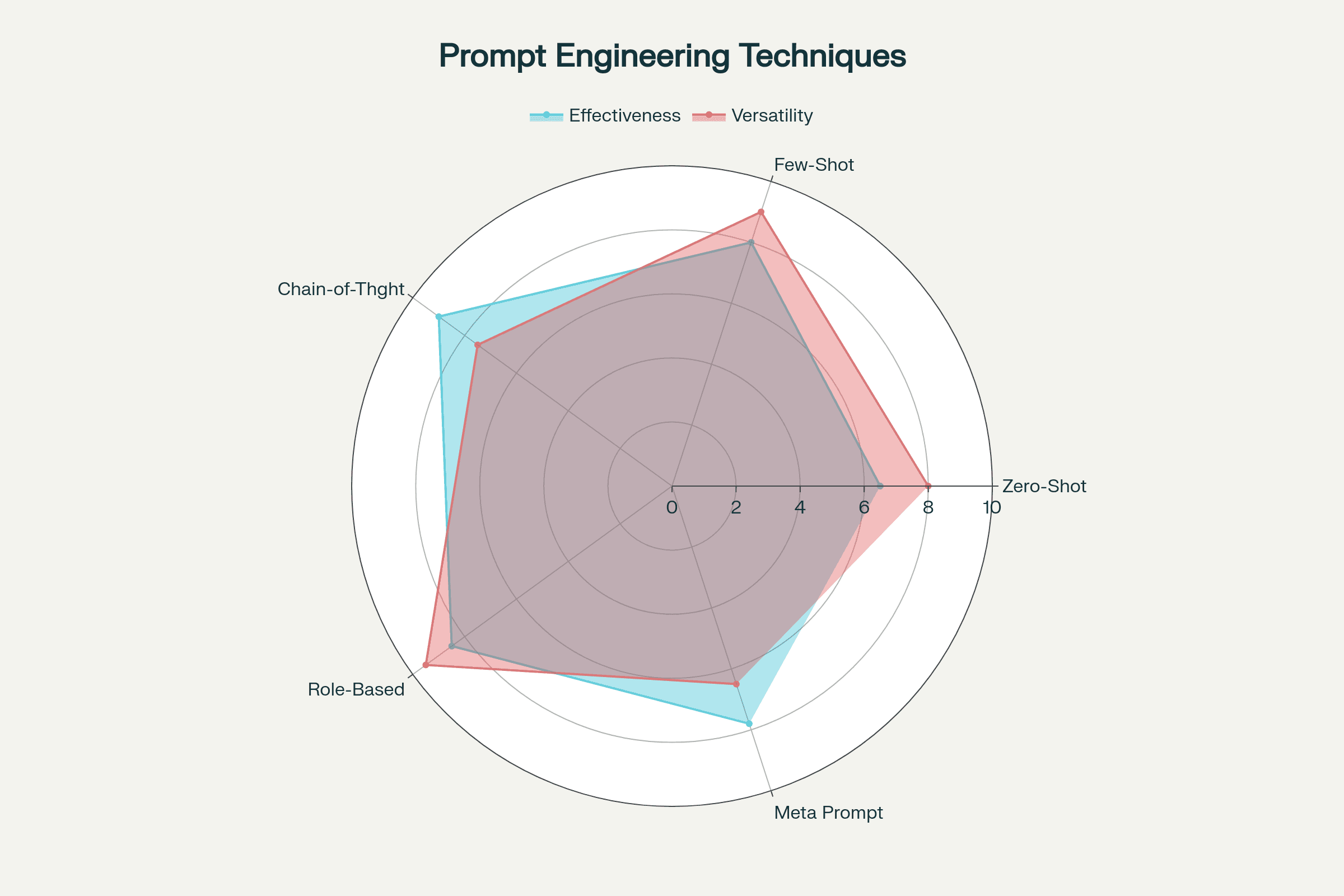
Effectiveness: Zero-shot approaches score 6.5/10 for effectiveness but 8.0/10 for versatility across use cases. The technique works broadly but lacks the precision of more advanced methods.
Best practices:
Use clear, specific instructions
Define desired output format upfront
Specify target audience when relevant
Keep prompts concise but complete
Few-Shot Prompting: Learning Through Examples
Few-shot prompting includes examples within the prompt to demonstrate the desired pattern, helping models understand context and style through demonstration rather than explanation.
When to use: Complex tasks requiring specific formatting, nuanced understanding, or particular stylistic choices. Content generation, classification tasks, and creative writing benefit significantly from few-shot approaches.
Example:
Effectiveness: Few-shot prompting achieves 8.0/10 effectiveness and 9.0/10 versatility. It represents the sweet spot of performance and flexibility for most applications.
Best practices:
Provide 2-5 diverse examples covering edge cases
Ensure examples align precisely with desired output format
Include both common and exceptional scenarios
Maintain consistency in example structure
Chain-of-Thought (CoT) Prompting: Reasoning Step-by-Step
Chain-of-thought prompting guides models to break down complex problems into intermediate reasoning steps, dramatically improving accuracy on tasks requiring logic, calculation, or multi-step inference.
When to use: Mathematical problems, logical reasoning, complex analysis, and any task where showing work improves accuracy. CoT excels when transparency matters as much as correctness.
Example:
Effectiveness: CoT prompting scores 9.0/10 for effectiveness though 7.5/10 for versatility. It delivers exceptional results on reasoning tasks but requires additional tokens and computation.
Best practices:
Explicitly request step-by-step reasoning ("Let's think step by step")
For simple problems, zero-shot CoT works ("Solve this step by step")
Combine with few-shot for complex, unfamiliar domains
Review reasoning chains to identify model logic errors
Role-Based Prompting: Persona-Driven Outputs
Role-based prompting assigns the AI a specific persona or expertise level, shaping response style, depth, and perspective.
When to use: When tone, expertise level, or perspective significantly impacts output quality. Professional communications, educational content, and specialized analysis benefit from defined roles.
Example:
Effectiveness: Role-based approaches achieve 8.5/10 effectiveness and 9.5/10 versatility. They adapt well to diverse scenarios while maintaining consistent quality.
Best practices:
Define expertise level explicitly (beginner, intermediate, expert)
Specify communication style (formal, conversational, technical)
Include relevant constraints ("avoid jargon," "use metaphors")
Test multiple personas to optimize for your use case
Meta Prompting: Abstract Structural Guidance
Meta prompting focuses on logical structures and formats rather than specific examples, providing abstract frameworks the model applies across situations.
When to use: Situations requiring consistent structure across varied content, or when creating reusable prompt templates. Particularly valuable for token-efficient operations at scale.
Example:
Effectiveness: Meta prompting scores 7.8/10 effectiveness and 6.5/10 versatility. It excels in structured environments but struggles with creative or open-ended tasks.
Best practices:
Keep frameworks abstract enough for multiple contexts
Define clear boundaries for each structural element
Use numbered steps or labeled sections
Iterate frameworks based on output quality
Advanced Prompting Frameworks
The SPEAR Framework
SPEAR (Situation, Problem, Expectation, Action, Result) provides a comprehensive structure for complex prompting scenarios:
This framework works exceptionally well for business communications, project planning, and analytical tasks where stakeholder alignment matters.
The ICE Framework
ICE (Instruction, Context, Examples) balances clarity with flexibility:
ICE particularly suits content generation, data transformation, and creative applications where examples clarify intent more effectively than lengthy instructions.
The CRAFT Framework
CRAFT (Capability, Role, Action, Format, Tone) delivers precise control for specialized applications:
CRAFT excels in technical documentation, professional communications, and domain-specific analysis requiring nuanced control.
Model-Specific Optimization
ChatGPT Optimization Strategies
ChatGPT responds best to structured, detailed prompts with clear formatting expectations:
Strengths: Technical writing, code generation, analytical tasks, summarization
Prompting style: Be specific and direct, use formatting indicators, define length explicitly
Best for: Tasks requiring accuracy and depth over creativity
Example optimization:
Claude Optimization Strategies
Claude excels with conversational, context-rich prompts that provide nuanced background:
Strengths: Creative writing, nuanced analysis, ethical reasoning, conversational depth
Prompting style: Open-ended questions, rich context, emphasis on exploration
Best for: Brainstorming, complex discussions, empathetic responses
Example optimization:
Claude-specific features:
Use XML-style tags for structure (optional but effective)
Provide ethical considerations and constraints explicitly
Build on previous conversation context
Emphasize nuance and complexity in your requests
Gemini Optimization Strategies
Google Gemini handles multimodal inputs and diverse examples particularly well:
Strengths: Multimodal analysis, diverse examples, creative problem-solving
Prompting style: Clear formatting, diverse examples, visual descriptions
Best for: Tasks involving images, varied content types, exploratory analysis
Example optimization:
Prompt Templates and Reusable Structures
Creating Effective Templates
Standardized templates ensure consistency while allowing customization for specific contexts:
Basic template structure:
Template benefits:
40% faster approval times for prompt-based workflows
55% increased productivity through reduced iteration
Consistent quality across team members and use cases
Modular Prompt Design
Modular approaches break prompts into reusable components that combine flexibly:
Core modules:
Goal module: Defines ultimate objective
Constraint module: Specifies limitations
Format module: Details output structure
Style module: Sets tone and approach
Implementation:
Advantages:
Swap modules for different contexts without rewriting
Test module variations independently
Scale across teams with consistent quality
Version control at module level
Common Prompting Mistakes and Solutions
Mistake 1: Ambiguous Instructions
The problem: Vague prompts like "How do I improve my business?" generate generic, unhelpful responses.
The fix: Add specific details about context, constraints, and desired outcomes:
Mistake 2: Overly Complex Prompts
The problem: Cramming multiple queries into a single prompt confuses models and produces incomplete responses.
The fix: Break complex requests into sequential, focused prompts:
Mistake 3: Lack of Persona/Perspective
The problem: Without defined perspective, outputs feel generic and misaligned with expectations.
The fix: Specify expertise level and role explicitly:
Mistake 4: Not Iterating Based on Output
The problem: Accepting first-generation responses rather than refining prompts based on results.
The fix: Implement systematic testing and refinement:
Generate initial output
Identify gaps or issues
Modify prompt addressing specific weaknesses
Test again and compare results
Document effective modifications
Mistake 5: Ignoring Model Limitations
The problem: Expecting AI to provide opinions, real-time information, or infallible accuracy.
The fix: Frame requests within model capabilities:
Request analysis of provided data rather than real-time information
Ask for multiple perspectives rather than definitive opinions
Verify factual claims through external sources
Use AI for ideation and drafting, human review for accuracy
Advanced Techniques for Complex Tasks
Prompt Chaining
Prompt chaining breaks complex objectives into sequential steps, with each output feeding the next prompt:
Process:
Benefits:
Handles complexity exceeding single-prompt capabilities
Enables validation at each step
Produces more accurate final outputs
Retrieval-Augmented Generation (RAG)
RAG enhances prompts with relevant information retrieved from trusted sources before generation:
Architecture:
Query triggers search across indexed documents
Relevant passages retrieved and ranked
Retrieved context injected into prompt
Model generates response grounded in provided information
Advantages:
Dramatically reduces hallucinations
Grounds outputs in verifiable sources
Enables domain-specific accuracy without fine-tuning
Implementation considerations:
Index high-quality, authoritative sources
Implement relevance ranking to surface best matches
Balance retrieved context length with token limits
Cite sources in generated outputs
Constrained Generation
Constrained generation uses parameters and explicit instructions to control output characteristics:
Techniques:
Industry-Specific Applications
Marketing and Content Creation
Key prompting strategies:
Define target persona demographics explicitly
Specify brand voice and tone requirements
Include competitive positioning context
Request multiple variations for A/B testing
Example:
Software Development
Key prompting strategies:
Specify programming language and version
Provide code context (existing structure, dependencies)
Define error handling requirements
Request comments and documentation
Example:
Data Analysis
Key prompting strategies:
Provide dataset schema and sample data
Specify analysis objectives and metrics
Define output format (narrative, tables, visualizations)
Request statistical confidence levels
Example:
Education and Training
Key prompting strategies:
Define learner knowledge level explicitly
Request examples and analogies
Include comprehension checks
Specify instructional approach
Example:
Measuring and Optimizing Prompt Performance
Key Performance Metrics
Accuracy: Does the output meet factual correctness standards?
Relevance: Does the response address the actual question asked?
Completeness: Are all required elements present?
Consistency: Do multiple generations produce similar quality?
Efficiency: Token usage and generation time relative to value
A/B Testing Prompts
Systematic testing methodology:
Define success criteria (accuracy, style, length, etc.)
Create prompt variations (typically 2-4 versions)
Generate multiple outputs per variation (minimum 5-10)
Evaluate against criteria (blind evaluation preferred)
Implement winner, document learnings
Example test:
Continuous Improvement Process
Establish feedback loops:
Collect outputs from production use
Identify patterns in failures or suboptimal results
Hypothesize improvements to prompt structure
Test modifications systematically
Document learnings in prompt library
Train team on updated best practices
The Future of Prompt Engineering
As AI models evolve, prompt engineering adapts:
Multimodal prompting: Combining text, images, audio, and video inputs for richer instructions
Automated prompt optimization: AI systems that refine prompts based on objective functions
Standardized frameworks: Industry-wide prompt engineering standards emerging
Specialized tools: Dedicated platforms for prompt management, testing, and optimization
Organizations investing in prompt engineering capabilities position themselves to maximize AI returns as models advance. The skill compounds over time—expertise developed today translates directly to next-generation systems.
Conclusion: Mastering the Human-AI Interface
Prompt engineering represents the critical interface between human intention and AI capability. As models become more powerful, the ability to articulate needs precisely and strategically becomes increasingly valuable.
The techniques covered in this guide—from foundational zero-shot approaches to advanced RAG implementations—provide a comprehensive toolkit for extracting maximum value from AI systems. But prompt engineering remains fundamentally experimental. The best practitioners combine structured frameworks with creative exploration, rigorous testing with intuitive refinement.
Start with the basics: clear instructions, appropriate context, and relevant examples. Progress to advanced techniques as your needs grow more sophisticated. Most importantly, maintain a systematic approach to learning from both successes and failures. Every interaction with AI provides data for improving your prompting strategy.
The organizations and individuals who master this skill will extract exponentially more value from AI investments than those who treat prompting as an afterthought. In 2025 and beyond, prompt engineering literacy represents a fundamental competency for knowledge workers across industries.
The future belongs to those who can speak AI fluently. This guide provides the language foundations—now it's time to practice the conversation.
Key Takeaways:
Prompt engineering quality directly impacts output accuracy, consistency, and efficiency
Chain-of-Thought prompting achieves 9.0/10 effectiveness for reasoning tasks
Model-specific optimization (ChatGPT, Claude, Gemini) requires different approaches
Systematic testing and iteration improve results 40%+ faster than ad-hoc methods
Advanced techniques like RAG and prompt chaining handle complexity beyond single prompts