Article
Nov 13, 2025
Synthetic Data 2025: Accelerate AI, Ensure Privacy
How enterprise teams use synthetic data to train, test, and scale AI—faster, safer, and compliant. Platforms, use cases, workflow, metrics, and regulatory guidance for 2025.

Introduction
Data is the oil of AI—but privacy and access are now equally critical.
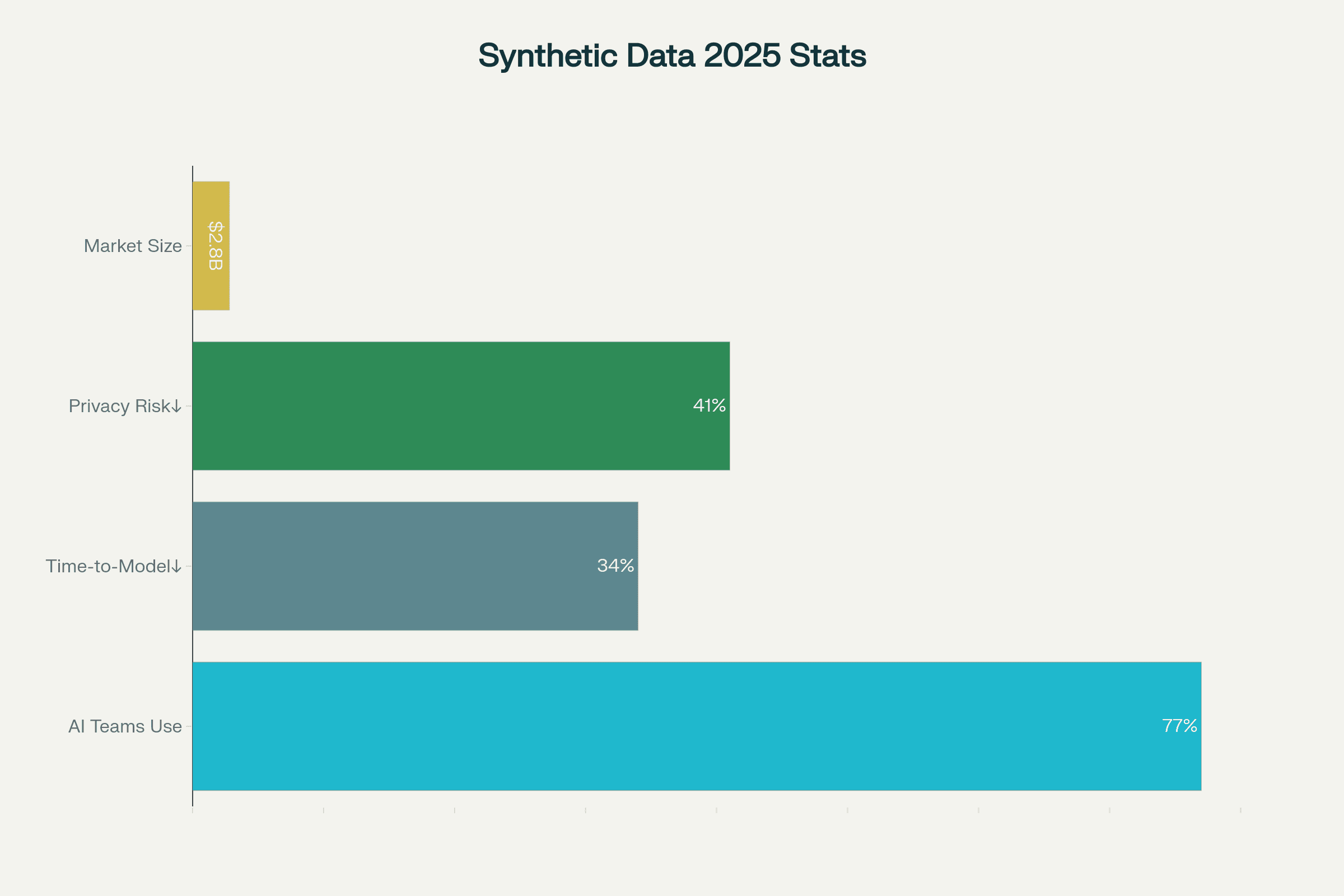
77% of enterprise AI teams now use synthetic data to train, validate, or debug models
34% decrease in AI dev cycle time on synthetic-first projects
Privacy risk reduced 41%, with synthetic data now accepted by most global regulators for model testing and compliance
7 High-Impact Synthetic Data Use Cases
Rare Event Simulation
Generate thousands of fraud, error, crash, fraud, or crisis records—solve “scarcity” with scalePrivacy-First AI Model Training
Build and tune ML/LLMs on data with zero real customer or patient recordsEdge Case Testing
Stress test models and pipelines on unseen, extreme, or intentionally “adversarial” inputsIoT & Sensor Data Creation
Simulate months/years of device, health, factory, or smart grid scenarios for ops teamsRegulatory Compliance & Sandbox
Share compliant, privacy-safe data with partners, vendors, and QAsConversational/NLP/LLM Pretraining
Create multilingual, balanced, made-for-purpose corpora where real world data is sparseBias & Drift Remediation
Fill gaps, rebalance classes, debias inputs across gender, ethnicity, event, or error type
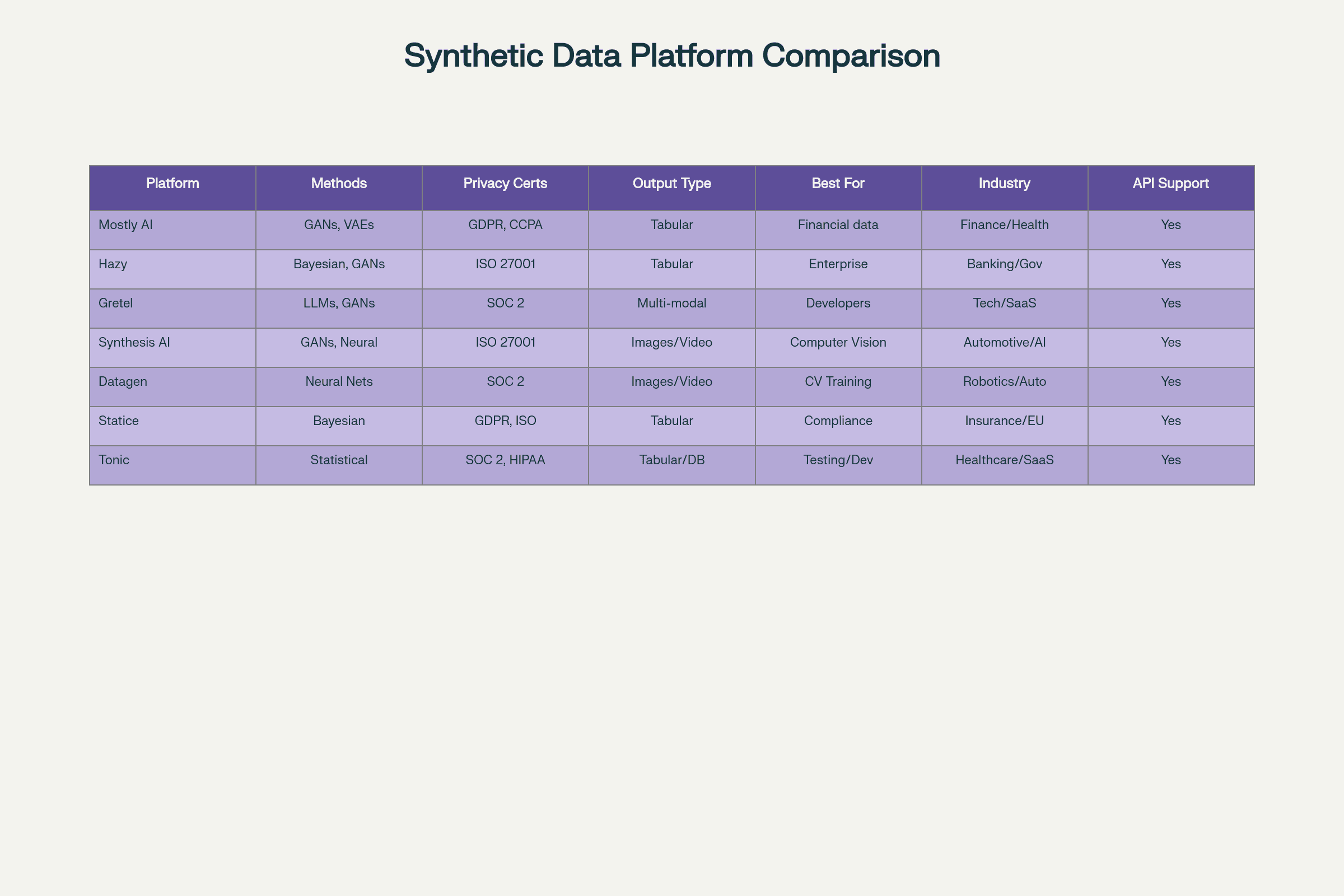
Platform Comparison: Synthetic Data Stack 2025
Platform | Gen Methods | Privacy Certs | Output Type | Best For |
|---|---|---|---|---|
Mostly AI | Tabular, time | GDPR, HIPAA | CSV, SQL, API | Banking, pharma |
Hazy | Tabular/text | GDPR, ISO | CSV, DB | Financial, gov't |
Gretel | Text, tabular | HIPAA, SOC2 | API, cloud, open | Dev/data science |
Synthetaic | Image/video | Open, custom | API, files | Vision, edge |
Datagen | 3D/video/image | NDA, SOC2 | Vision, AR/VR | IoT, automotive |
Statice | Tabular, time | GDPR/SOC2 | Data lake, API | Healthcare, B2B |
Tonic | SQL/tabular | HIPAA/GDPR | DB, API | Dev, SaaS |
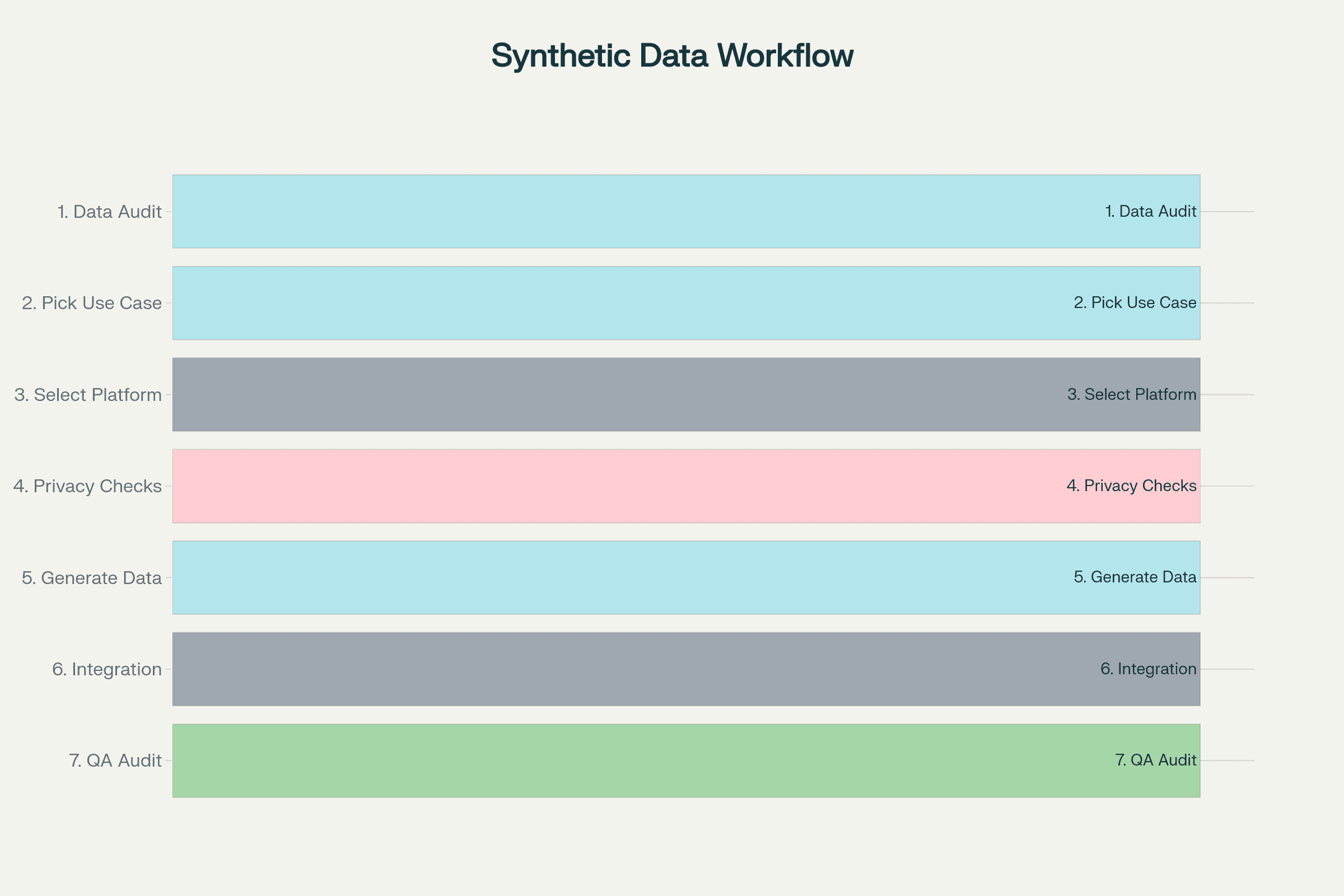
Synthetic Data Project: 7-Step Workflow
Source data audit/classification:
Catalog inputs, flag PII, risk, compliance exposuresDefine project/use case:
Model training, testing, sharing; pick goal and ROIPlatform or algorithm selection:
Third-party, open-source, or custom?Privacy controls and risk checks:
Mask, transform, or obfuscate critical fields before genGenerate and validate synthetic data:
QA for utility, fidelity, and absence of leakageIntegrate and deploy with ML models/tools:
Replace/train, test, and hand off to dev/opsAudit and regulatory sign-off:
Compare to real, document bias/safety, prep for compliance review
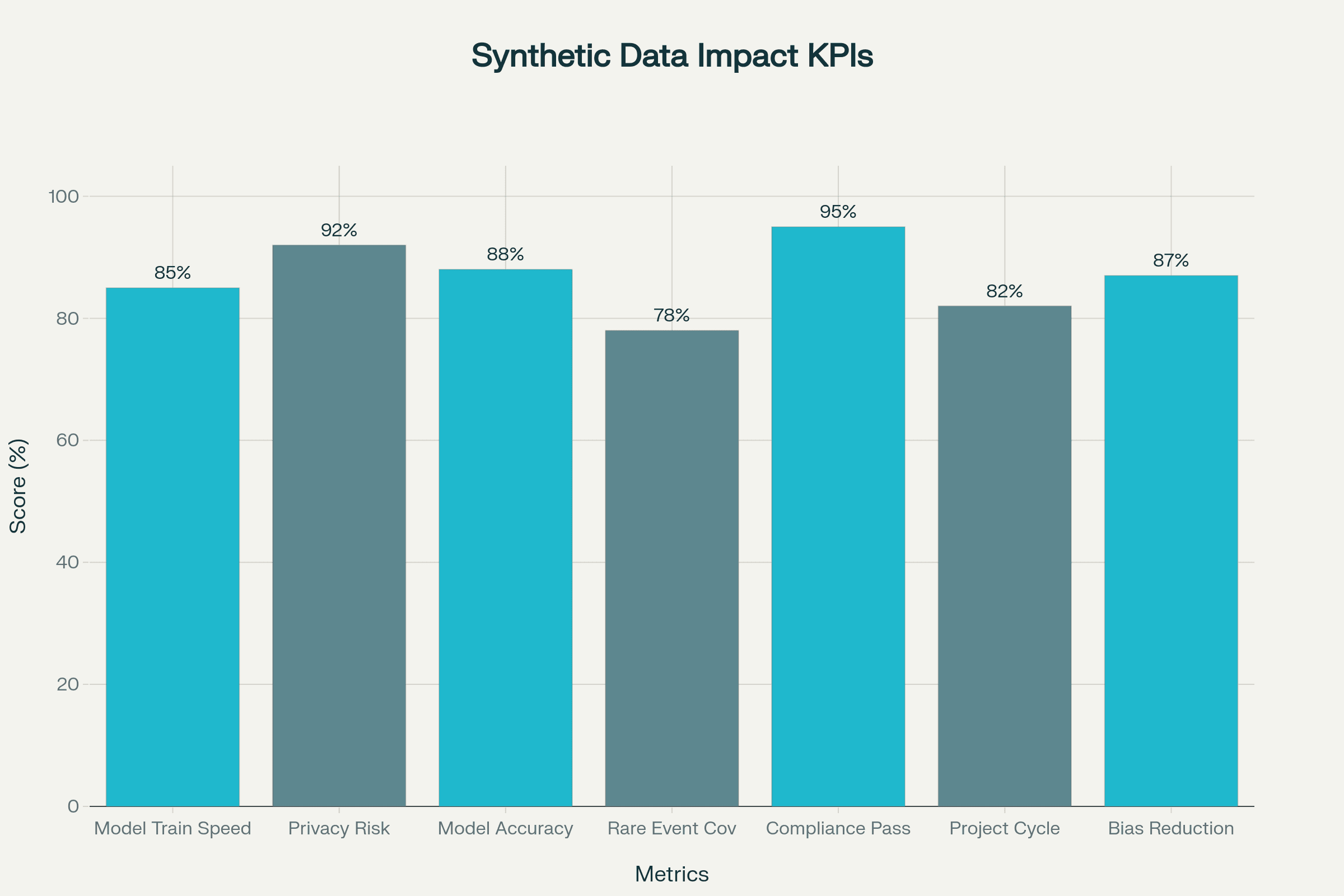
KPIs & Success Metrics
Model development speed (days/weeks)
Privacy risk/dq flags (per release)
Synthetic vs. real data model accuracy
Rare event coverage (# of test cases)
Compliance test/pass rate
Bias reduction (% improvement)
Cycle time to deployment
Common Pitfalls—And Safeguards
Low-quality or incomplete source data: start with a full, clean audit
Privacy leakage: overfitted or too-similar synthetic data must be flagged, reviewed, or thrown out
Overfitting to training data: regular rotation/QA, introduce variability
Bad documentation: log process, sampling, and QA for compliance/reporting
Model drift: retrain synthetic as real-world data/processes change
Ignoring bias: QA for over- or under-representation in generated sets
Regulatory miss: ensure full traceability, test in compliance sandbox